Vojta Machytka

Data Scientist
MIT Sloan Master of Business Analytics
Email: vojta97@mit.edu
LinkedIn: linkedin.com/in/vmachytka
-
![]()
4+ Years of Experience in Data Analysis and Statistical Modeling
Proven expertise in statistical analysis, machine learning, and time series regression across multiple high-impact projects.
-
![]()
Client-Facing Role Expertise
Comfortable communicating complex data insights effectively to diverse audiences, including executives and non-technical stakeholders.
-
![]()
Proficient in Advanced Data Tools and Techniques
Skilled in Python, SQL, and Tableau with a deep understanding of advanced machine learning techniques and their business applications.



Data Science Projects
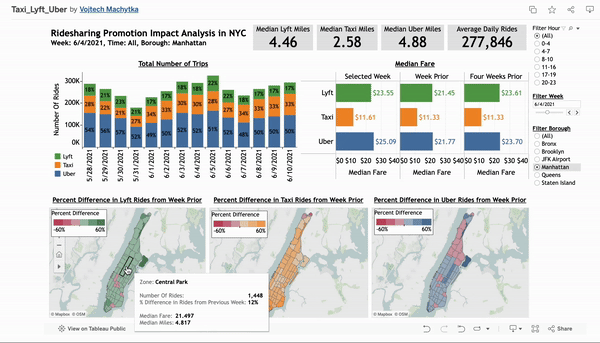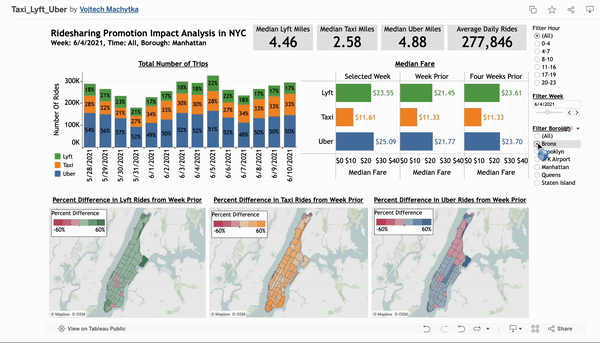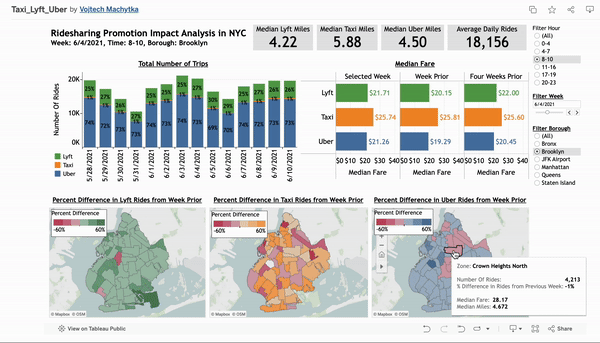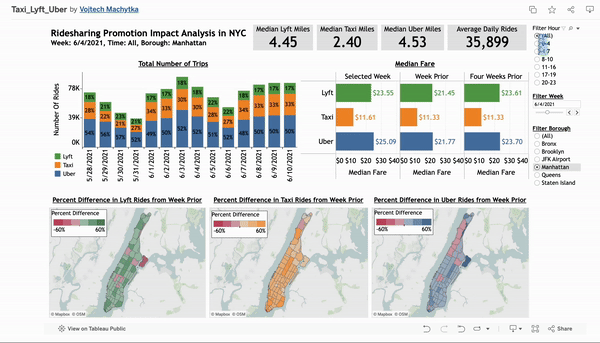
Ride-Sharing Promotion Impact Analysis in NYC
Developed an interactive Tableau dashboard analyzing 2021 ride-sharing data from Uber, Lyft, and taxis in NYC to evaluate the impact of a promotion in a specific borough. This tool provides ride-sharing managers with actionable insights on market trends, fare fluctuations, and geographic usage patterns to inform strategic decisions and optimize market presence.

Redlining, Speculation, Displacement in the City of Boston
Partnered with the Metropolitan Area Planning Council to build a scrollytelling website featuring five interactive visualizations using React and D3 in JavaScript. This project provided crucial insights to policymakers on the impact of speculative investment on resident displacement, influencing policy decisions by highlighting historical redlining and current investment trends in Boston, aiming to protect vulnerable communities.
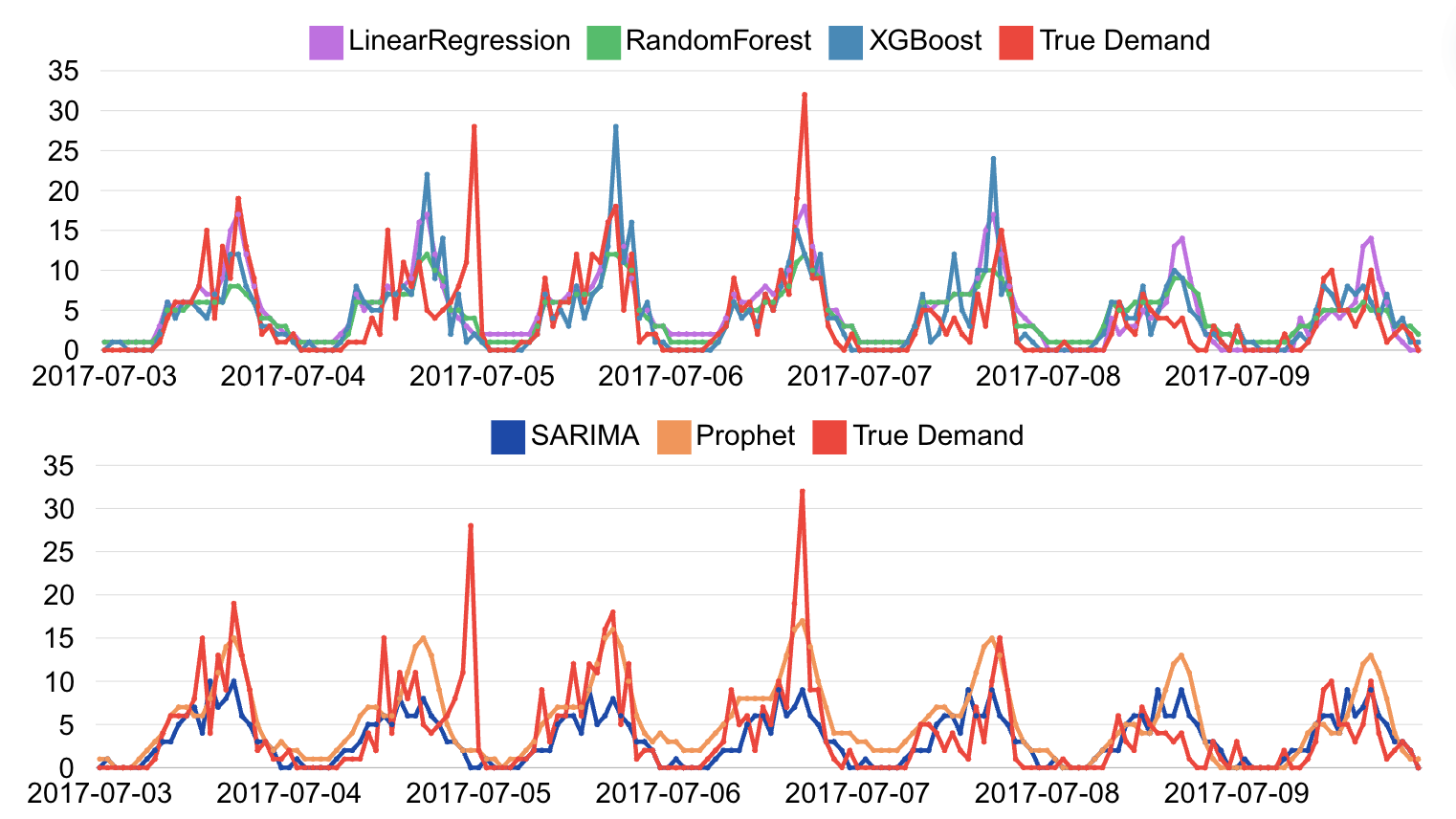
Predicting Hourly Demand for Boston BlueBike Service
Forecasted hourly BlueBike demand using Random Forest, XGBoost, Prophet, and SARIMA time series models in R with a precision of within 2 bikes, informing strategic dock allocation to enhance system efficiency. Analyzed over 5.4 million bike trips and weather data from 2017-2019, identifying key factors such as temperature and commuter hours to optimize resource allocation and improve customer satisfaction.
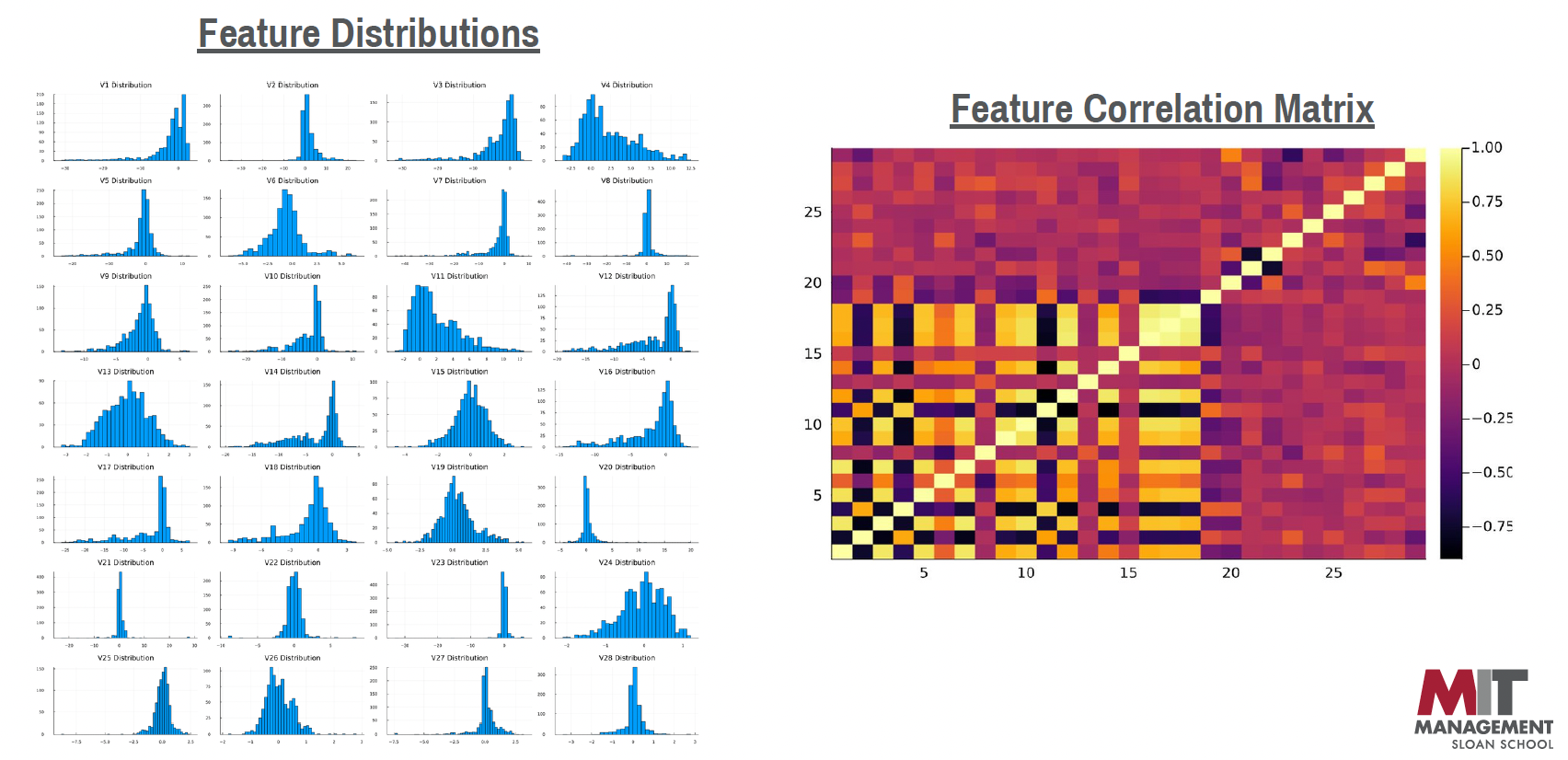
Financial Fraud Detection System
Engineered a comprehensive financial fraud detection system utilizing Neural Networks, Optimal Classification Trees, Random Forest, and XGBoost on a dataset of over 200K credit card transactions. This system accurately pinpointed fraudulent activities with over 90% accuracy.
Data Science Experience

Data Scientist (2025 - Present)
At CVS Health (Aetna), I build data science solutions that improve care management efficiency and transparency for millions of members nationwide. I developed end-to-end risk stratification pipelines in BigQuery and Vertex AI to segment 20+ million members by risk level, enabling the identification of high-cost patients and supporting targeted interventions across care programs. In parallel, I created a Gemini-based explainability pipeline to translate Claims transformer embeddings and model outputs into plain-language insights, improving model interpretability and reducing ad-hoc analysis time by 35%. These projects strengthened my expertise in Google Cloud Platform tools and demonstrated the potential of LLMs to enhance healthcare decision-making at scale.
Skills: Python · Large Language Models · Generative AI · Natural Language Processing · Data Classification · Data Analysis · Data Visualization · Communication

Data Scientist II / Data Science Intern (2024 - 2025)
At McKinsey, I worked on two major Generative AI initiatives that enhanced how knowledge and data were managed across the firm. During my internship, I automated the abstract creation and classification of over 50,000 documents using Large Language Models and named entity recognition in Python, improving accuracy by 56% and reducing run-time by 83%. After joining full-time, I developed an AI-powered document sanitization system that identifies and redacts sensitive information across 26,000 files each year, saving analysts significant time and strengthening data governance. Together, these projects deepened my experience in applying advanced analytics and machine learning at scale to improve operational efficiency and knowledge accessibility for a 40,000+ user platform.
Skills: Python · Large Language Models · Generative AI · Natural Language Processing · Data Classification · Exploratory Data Analysis · Communication

Data Science Intern (2023)
At ClassHook, I spearheaded the automation of classifying over 7,200 educational clips into more than 100 academic subjects using natural language processing (NLP) techniques and LLMs in Python. This project resulted in a 70% reduction in video categorization time, boosting content curation for K-12 educators. I also designed an intuitive API-based platform in Gradio and regularly presented findings to the CEO, effectively guiding the implementation of our automation solution.
Skills: Python · Large Language Models · Generative AI · Natural Language Processing · Data Classification · Data Analysis · Data Visualization · Communication
Senior Analyst (2020 - 2023)
At FTI Consulting (within their economic consulting subsidiary Compass Lexecon), I collected, processed, and analyzed over 100 million data points to shape expert testimony and guide strategic decisions for leading U.S. and foreign airlines. My work involved conducting statistical and time series regression analyses in Stata and R, as well as creating dynamic data visualizations and dashboards in Tableau. These efforts supported decision-making processes for airline executives, legal teams, and economists. I also devised and led a three-week new hire training program, fostering a welcoming work environment for incoming hires.
Skills: Regression Analysis · Data Collection · Visualization · Tableau · R · Economic Research · Leadership · Stata - Software for Statistics and Data Science · Econometric Modeling · Microsoft Excel · Analytical Skills · Communication
Co-President of a DEI Initiative

Organized Mental Health Awareness Events
Initiated events focusing on mental health awareness, creating a supportive environment for open discussions and providing resources to help manage stress and well-being.
Diverse Cultural Celebrations
Organized trivia events celebrating Black History Month, Juneteenth, and other cultural milestones, enabling people to learn about their importance in a fun and engaging way.
Hosted Expert Speakers
Hosted PhD speakers to present their research on the gender wage gap and other diversity topics, fostering an inclusive environment and sparking engaging conversations among coworkers across all levels of the company.